
There are two primary forms of pruning:
- Pre-pruning involves pruning the tree during its construction. The method assesses at each node if dividing the node further will enhance the overall performance on the validation data. If not, the node is designated as a leaf without additional division.
- Post-pruning, also known as pruning the tree, consists of constructing the full tree and thereafter eliminating nodes that do not contribute significantly to predictive power. This is usually accomplished by methods such as cost-complexity pruning.
Decision trees that are trained on any training data run the risk of overfitting the training data.
What we mean by this is that eventually each leaf will reperesent a very specific set of attribute combinations that are seen in the training data, and the tree will consequently not be able to classify attribute value combinations that are not seen in the training data.
In order to prevent this from happening, we must prune the decision tree.
By pruning we mean that the lower ends (the leaves) of the tree are “snipped” until the tree is much smaller. The figure below shows an example of a full tree, and the same tree after it has been pruned to have only 4 leaves.
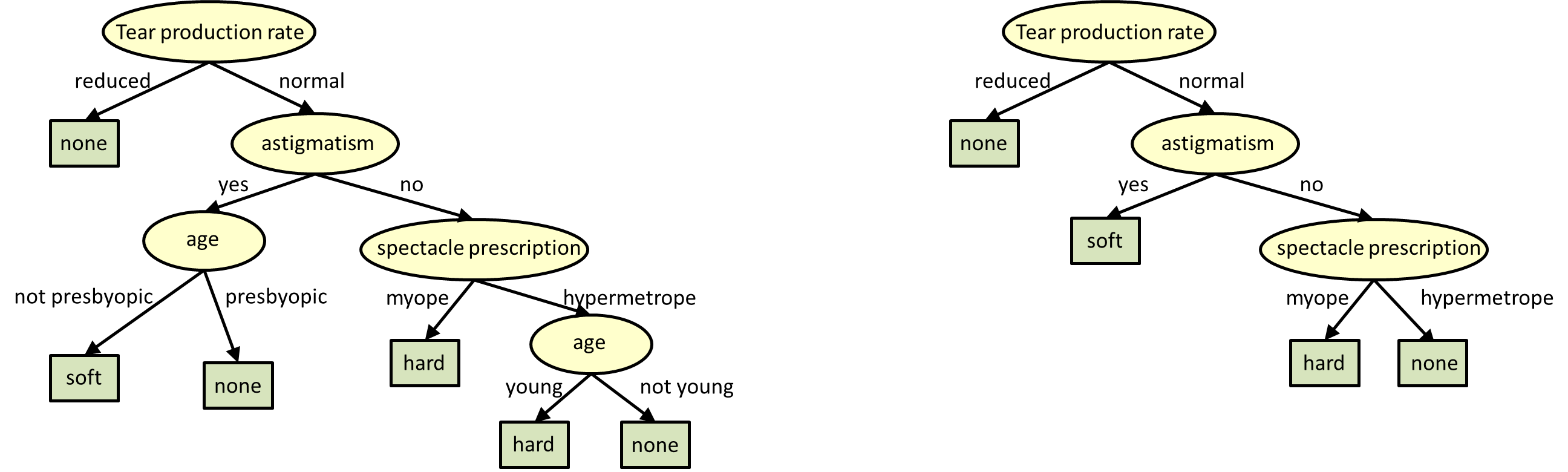
Caption: The figure to the right is a pruned version of the decision tree to the left.
Pruning can be performed in many ways. Here are two.
Pruning by Information Gain
The simplest technique is to prune out portions of the tree that result in the least information gain. This procedure does not require any additional data, and only bases the pruning on the information that is already computed when the tree is being built from training data.The process of IG-based pruning requires us to identify “twigs”, nodes whose children are all leaves. “Pruning” a twig removes all of the leaves which are the children of the twig, and makes the twig a leaf. The figure below illustrates this.

Caption: Pruning the encircled twig in the left figure results in the tree to the right. The twig now becomes a leaf.
The algorithm for pruning is as follows:
- Catalog all twigs in the tree
- Count the total number of leaves in the tree.
- While the number of leaves in the tree exceeds the desired number:
- Find the twig with the least Information Gain
- Remove all child nodes of the twig.
- Relabel twig as a leaf.
- Update the leaf count.
Pruning by Classification Performance on Validation Set
An alternate approach is to prune the tree to maximize classification performance on a validation set (a data set with known labels, which was not used to train the tree).
We pass the validation data down the tree. At each node, we record the total number of instances and the number of misclassifications, if that node were actually a leaf. We do this at all nodes and leaves.
Subsequently, we prune all twigs where pruning results in the smallest overall increase in classification error.
The overall algorithm for pruning is as follows:
Stage 1:
- For each instance of validation data:
- Recursively pass
- Find the twig with the least Information Gain
- Remove all child nodes of the twig.
- Relabel twig as a leaf.
- Update the leaf count.
Other forms for pruning
Pruning may also use other criteria, e.g. minimizing computational complexity, or using other techniques, e.g. randomized pruning of entire subtrees.
0 comments :
Post a Comment
Note: only a member of this blog may post a comment.